the project(and the blog) is Work in progress i have just submitted a basic working model the performance of the model isn’t great as i am limited by time and hardware but i will highlight in this blog what can be done to greatly improve on those and several other metrics
Basic Overview:
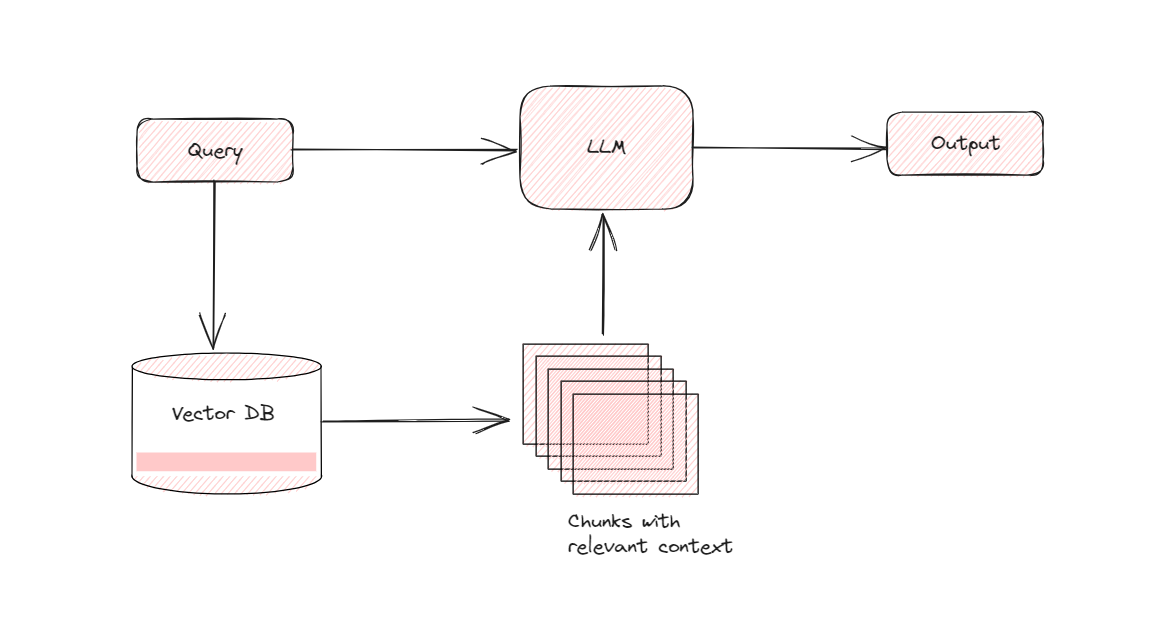
The basic overveiw of the rag system is that the
IR-system:
- The IR system uses Faiss library for indexing and retriving answers
- There is no persistence yet, and an actual database saved on disk (something to work on)
- The indexings method is just simple ranking similarity scores, indexes like HNSW, or Tree index do well with IR systems for Retrival Augmented Generators
Embeddings model
- The word embeddings model used in the IR system is ‘distilbert-base-uncased’ however we can use a finetuned model on the domain specific dataset to achieve better results as done by these kaggle competition winners
- Similar to how they trained on the wikipedia corpus model could train on (for example) aws docs as in the placebo pdf
LLM:
- for the llm i have used python bindings for llama.cpp with the google gemma 2b parameter model of course there are a lot of shortcomings to it but i am limited by hardware and time so i went with it.
- Ideally there are a lot of LLM’s on huggingface finetuned specifically on “Instruct Tuned datasets” which are used to train small sized llm’s for RAG’s
Assessing the model
One great way of assessing the model is:
- To generate a high quality dataset on your specific task through the api’s google gemini offers since their 1 million context window would be pretty good at answering long form inputs, and we could instruct it to format the output however we like (cite the place it found the answer)
- Both the embeddings model and the IR system could be assessed pretty well through a devops pipeline like the ones mlflow offer or through Weights and Biases.
- The dataset generated by the gemini model could be used to evaluate against the results of the IR systems by setting ground truth values and then evaluating based on different metrics such as similarity scores , recall , f1 score etc.
Overall / Other improvements:
- …
Docs
There are 3 main modules as of now running the code
chat.py
Code Snippet Overview
This code snippet demonstrates the process of using a PDF processor to extract text from a PDF file, indexing the text for search, and using an AI model (specifically, Llama) to provide answers based on user queries.
Imports
Llamafromllama_cpp: Represents an AI model (Llama) for generating responses.TextSearchfromindexing: Represents a class for searching text.PDFProcessorfromprocess_document: Represents a class for processing PDF documents.
Usage
-
PDF Processing:
- Create a
PDFProcessorobject with the path to the PDF file. - Chunk the text content of the PDF into smaller segments, here with a chunk size of 100 characters.
- Create a
-
Text Indexing:
- Initialize a
TextSearchobject with the chunked text corpus. - Perform a search for a specific query in the indexed text.
- Initialize a
-
User Interaction:
- Take user input for a question/query.
- Utilize the Llama AI model to generate responses based on the provided context and user query.
Code Snippet:
from llama_cpp import Llama
from indexing import TextSearch
from process_document import PDFProcessor
# Initialize PDFProcessor with the path to the PDF file
pdf_processor = PDFProcessor("./87286_92960v00_Decoding_Wireless.pdf")
# Chunk the text content of the PDF into smaller segments (chunk size: 100 characters)
corpus = pdf_processor.chunk_text(100)
# Initialize TextSearch with the chunked text corpus
text_search = TextSearch(corpus)
# Perform a search for a specific query in the indexed text
query = "what is radio"
results, ti = text_search.search(query)
print(ti, results)
# User interaction
chat = input("ask a question: ")
# Initialize Llama model
llm = Llama(model_path="/home/dumball/gemma-2b-it-q4_k_m.gguf")
# Generate response using Llama model
output = llm(f"context: {ti} answers based on this context only \indexing.py
code snippet
import numpy as np
import faiss
import torch
from transformers import AutoTokenizer, AutoModel
#from docy import PDFProcessor
class TextSearch:
def __init__(self, texts, model_name='distilbert-base-uncased'):
# Initialize the tokenizer and model from Hugging Face
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModel.from_pretrained(model_name)
# Encode the texts
self.texts = texts
self.text_embeddings = self._encode_texts(texts)
# Dimension of the vectors
self.d = self.text_embeddings.shape[1]
# Create a FAISS index
self.index = faiss.IndexFlatL2(self.d)
# Add the text embeddings to the FAISS index
self.index.add(self.text_embeddings)
def _encode_texts(self, texts):
# Tokenize input texts
encoded_input = self.tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Get the model's last hidden states
with torch.no_grad():
model_output = self.model(**encoded_input)
# Mean pooling here, but you can also try max pooling or CLS token
return model_output.last_hidden_state.mean(dim=1).cpu().numpy()
def search(self, query, k=2):
# Encode the query
query_embedding = self._encode_texts([query])[0]
# Search the index
distances, indices = self.index.search(np.array([query_embedding]), len(self.texts))
# Return the indices of the texts along with their distances, sorted by similarity
ranked_texts = {self.texts[i]:distances[0][j] for j, i in sorted(enumerate(indices[0]), key=lambda x: x[1])}
#ranked_texts = {(self.texts[i], distances[0][j]) for j, i in sorted(enumerate(indices[0]), key=lambda x: x[1])}
top_indices = dict(sorted(ranked_texts.items(), key=lambda item: item[1])[:k])
return ranked_texts, top_indices
def get_top_texts(self, query, k=2):
# Encode the query
query_embedding = self._encode_texts([query])[0]
# Search the index
_, indices = self.index.search(np.array([query_embedding]), len(self.texts))
# Get the top k indices
top_indices = indices[0][:k]
# Retrieve the texts corresponding to the top indices
top_texts = [self.texts[idx] for idx in top_indices]
return top_textsUses the faiss library to:
search(self, query, k=2)
Searches the indexed texts for the most similar ones to the given query.
Parameters:
query(str): The text query to search for similarities.k(int, optional): The number of top similar texts to retrieve. Defaults to 2.
Returns:
ranked_texts(dict): A dictionary containing the ranked texts along with their similarity distances. Keys are the texts, and values are the distances.top_indices(dict): A dictionary containing the top k texts with their similarity distances. Keys are the texts, and values are the distances.
get_top_texts(self, query, k=2)
Retrieves the top k similar texts to the given query.
Parameters:
query(str): The text query to find similar texts.k(int, optional): The number of top similar texts to retrieve. Defaults to 2.
Returns:
top_texts(list): A list containing the top k similar texts.
doc_process.py
PDFProcessor
A class for processing PDF files.
Methods:
__init__(self, pdf_path)
Initialize the PDFProcessor object with the path to the PDF file.
Parameters:
pdf_path(str): The path to the PDF file.
process_pdf(self)
Process the PDF file and extract its text content.
Returns:
all_text(str): The combined text content of all pages in the PDF file.
Raises:
FileNotFoundError: If the specified PDF file is not found.Exception: If an error occurs during processing.
Note: This method also prints metadata information if available.