Abstract
Transformer-Based Deep Learning for Vandalism Detection: An Overview
Vandalism detection in computer vision has seen significant advancements through the adoption of deep learning techniques, particularly leveraging transformer architectures. This paper provides a succinct overview of the landscape, focusing on the integration of transformers for improved detection accuracy and efficiency.
The review encompasses critical aspects such as feature extraction, classification methodologies, dataset curation, and real-world deployment considerations. Special attention is given to the transformative impact of transformer models in handling complex vandalism detection tasks, showcasing their ability to capture long-range dependencies and contextual information effectively.
Furthermore, ethical implications surrounding automated surveillance systems are briefly discussed, emphasizing the importance of privacy preservation and algorithmic fairness. By synthesizing current advancements and outlining future prospects, this overview serves as a valuable reference for researchers and practitioners aiming to harness transformer-based deep learning for vandalism detection in computer vision.
Intorduction
In recent years, the proliferation of digital media and the exponential growth of video content across various online platforms have underscored the importance of effective video analysis and understanding. From surveillance footage to social media clips, videos encapsulate a wealth of information, making them valuable assets for numerous applications, including security, entertainment, and marketing. However, unlocking the insights embedded within videos necessitates sophisticated algorithms capable of comprehensively parsing and interpreting their contents.
Traditional approaches to video analysis have often relied on frame-by-frame processing or feature engineering techniques, which may struggle to capture temporal dependencies and holistic context effectively. In response to these challenges, the emergence of deep learning has revolutionized the field, offering powerful tools for end-to-end video understanding. Within the realm of deep learning, convolutional neural networks (CNNs) have demonstrated remarkable success in image-related tasks, while recurrent neural networks (RNNs) and variants like long short-term memory (LSTM) networks have shown efficacy in sequential data analysis. However, these architectures often face limitations in capturing long-range dependencies and handling variable-length inputs inherent to video data.
To address these shortcomings and advance the frontier of video analysis, researchers have increasingly turned to models specifically designed for video understanding. One such paradigm-shifting architecture is the Video Transformer, an adaptation of the transformer model originally proposed for natural language processing tasks. The transformer architecture, characterized by its self-attention mechanism and parallel processing capabilities, has shown remarkable prowess in capturing both spatial and temporal relationships in videos, leading to state-of-the-art performance in various video-related tasks.

In this project, we propose the utilization of a Video Transformer model for comprehensive video understanding and analysis. By leveraging the inherent strengths of transformers in modeling long-range dependencies and contextual information, we aim to surpass the limitations of traditional approaches and existing deep learning architectures in video analysis tasks. Through a combination of self-attention mechanisms and parallel processing, the proposed Video Transformer model promises to offer superior performance in tasks such as action recognition, video summarization, anomaly detection, and more.
Furthermore, we envision the potential applications of the Video Transformer model across diverse domains, including surveillance and security, multimedia content creation, human-computer interaction, and autonomous systems. By elucidating the principles underlying the Video Transformer architecture and demonstrating its efficacy through empirical evaluation, this paper seeks to catalyze further research and innovation in the field of video analysis, paving the way for enhanced understanding and utilization of this rich source of visual information.
Literature review
Literature Review:
Video representation learning has garnered substantial attention in recent literature, with various supervised, semi-supervised, and self-supervised methods explored to capture rich temporal dynamics and contextual information within videos. Supervised learning approaches often rely on pre-trained image backbones, fine-tuned on video datasets for action classification [58, 75, 69, 10, 6]. Additionally, some methods directly train video backbones from video data in a supervised manner [67, 22, 21]. Semi-supervised learning techniques leverage labeled training samples to generate supervision signals for unlabeled ones, contributing to enhanced representation learning [59]. However, these methods predominantly follow a top-down training paradigm, potentially overlooking the intrinsic structure of video data.
Contrastingly, self-supervised learning paradigms aim to exploit temporal information through pretext tasks for self-supervised video representation learning [78, 44, 82, 5]. Recent trends have seen the proliferation of contrastive learning techniques for improved visual representation learning [28, 45, 29, 52, 24, 27], albeit with heavy reliance on data augmentation and large batch sizes [23]. Some approaches utilize autoencoders for video clip prediction, leveraging CNN or LSTM backbones, or even autoregressive models like GPT for video generation [48, 61, 83].
In the domain of masked visual modeling, efforts have primarily focused on image-based tasks, employing masking and reconstruction pipelines. These methodologies, originally proposed for denoised autoencoders [71] or context-based inpainting [47], have evolved to include sequence prediction approaches like iGPT [11] and token prediction as in ViT [20]. Transformer-based architectures have gained traction in masked visual modeling, inspired by the success of BERT [17], with models like BEiT, BEVT, and VIMPAC adopting token prediction strategies [4, 76, 64]. Additionally, MAE introduced an asymmetric encoder-decoder architecture for masked image modeling [30], while MaskFeat proposed reconstructing HOG features of masked tokens for self-supervised pre-training in videos [79].
Inspired by the successes and innovations in masked visual modeling, VideoMAE introduces a novel approach to self-supervised video representation learning, specifically tailored for efficiency and effectiveness. Unlike previous masked video modeling methods, VideoMAE adopts a simpler yet more efficient video masked autoencoder approach, directly reconstructing pixels with plain ViT backbones, marking a significant advancement in self-supervised video pre-training frameworks.
Problem Identification & 0bjectives
System Methodology
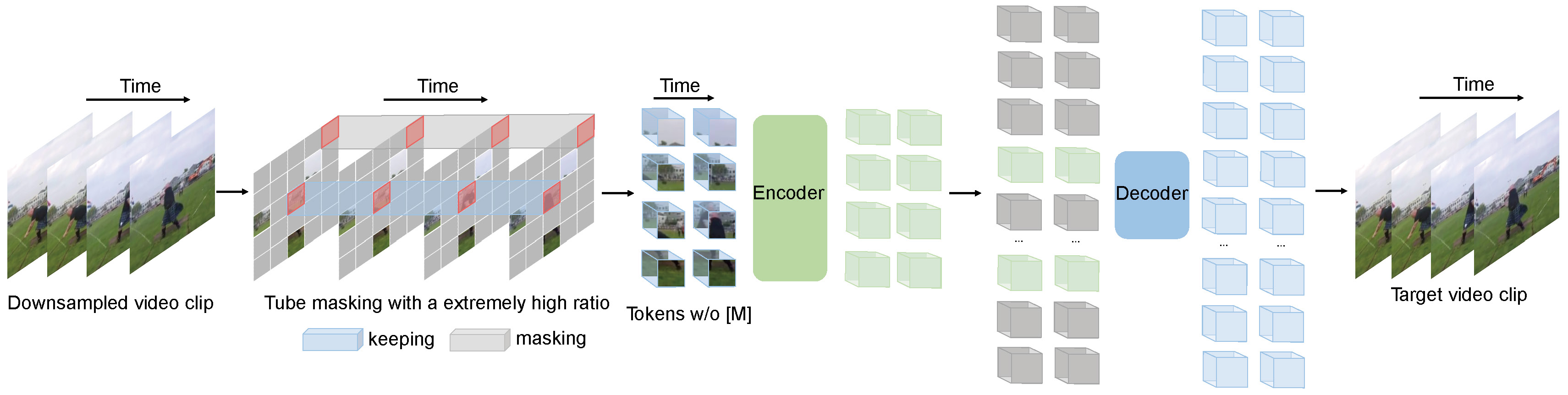
ImageMAE (Masked Autoencoder for Images) [30] employs an asymmetric encoder-decoder architecture to perform the masking and reconstruction task. Initially, the input image undergoes division into regular non-overlapping patches of size , with each patch represented by token embeddings. Subsequently, a subset of tokens undergoes random masking with a high masking ratio (75%), and only the remaining tokens are passed through the transformer encoder . Finally, a shallow decoder is placed atop the visible tokens from the encoder along with learnable mask tokens to reconstruct the image. The loss function utilized is the mean squared error (MSE) loss between the normalized masked tokens and the reconstructed ones in the pixel space
Figure: Slowness is a general prior in (a) video data [87]. This leads to two important characteristics in time: temporal redundancy and temporal correlation. Temporal redundancy makes it possible to recover pixels under an extremely high masking ratio. Temporal correlation leads to easily reconstruct the missing pixels by finding those corresponding patches in adjacent frames under plain (b) frame masking or (c) random masking. To avoid this simple task and encourage learning representative representation, we propose a (d) tube masking, where the masking map is the same for all frames.
Dataset : UCF - crime dataset

The UCF-Crime dataset is a large-scale dataset of 128 hours of videos. It consists of 1900 long and untrimmed real-world surveillance videos, with 13 realistic anomalies including Abuse, Arrest, Arson, Assault, Road Accident, Burglary, Explosion, Fighting, Robbery, Shooting, Stealing, Shoplifting, and Vandalism. These anomalies are selected because they have a significant impact on public safety.
This dataset can be used for two tasks. First, general anomaly detection considering all anomalies in one group and all normal activities in another group. Second, for recognizing each of 13 anomalous activities.
Implementation
Importing
import cv2
import gradio as gr
import imutils
import numpy as np
import torch
from pytorchvideo.transforms import (
ApplyTransformToKey,
Normalize,
RandomShortSideScale,
RemoveKey,
ShortSideScale,
UniformTemporalSubsample,
)
from torchvision.transforms import (
Compose,
Lambda,
RandomCrop,
RandomHorizontalFlip,
Resize,
)
from transformers import VideoMAEFeatureExtractor, VideoMAEForVideoClassificationInitialise model and contants
MODEL_CKPT = "archit11/videomae-base-finetuned-fight-nofight-subset2"
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
MODEL = VideoMAEForVideoClassification.from_pretrained(MODEL_CKPT).to(DEVICE)
PROCESSOR = VideoMAEFeatureExtractor.from_pretrained(MODEL_CKPT)
RESIZE_TO = PROCESSOR.size["shortest_edge"]
NUM_FRAMES_TO_SAMPLE = MODEL.config.num_frames
IMAGE_STATS = {"image_mean": [0.485, 0.456, 0.406], "image_std": [0.229, 0.224, 0.225]}
VAL_TRANSFORMS = Compose(
[
UniformTemporalSubsample(NUM_FRAMES_TO_SAMPLE),
Lambda(lambda x: x / 255.0),
Normalize(IMAGE_STATS["image_mean"], IMAGE_STATS["image_std"]),
Resize((RESIZE_TO, RESIZE_TO)),
]
)
LABELS = list(MODEL.config.label2id.keys())
Data pre-processing for inference:
def parse_video(video_file):
"""A utility to parse the input videos.
Reference: https://pyimagesearch.com/2018/11/12/yolo-object-detection-with-opencv/
"""
vs = cv2.VideoCapture(video_file)
# try to determine the total number of frames in the video file
try:
prop = (
cv2.cv.CV_CAP_PROP_FRAME_COUNT
if imutils.is_cv2()
else cv2.CAP_PROP_FRAME_COUNT
)
total = int(vs.get(prop))
print("[INFO] {} total frames in video".format(total))
# an error occurred while trying to determine the total
# number of frames in the video file
except:
print("[INFO] could not determine # of frames in video")
print("[INFO] no approx. completion time can be provided")
total = -1
frames = []
# loop over frames from the video file stream
while True:
# read the next frame from the file
(grabbed, frame) = vs.read()
if frame is not None:
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frames.append(frame)
# if the frame was not grabbed, then we have reached the end
# of the stream
if not grabbed:
break
return frames
def preprocess_video(frames: list):
"""Utility to apply preprocessing transformations to a video tensor."""
# Each frame in the `frames` list has the shape: (height, width, num_channels).
# Collated together the `frames` has the the shape: (num_frames, height, width, num_channels).
# So, after converting the `frames` list to a torch tensor, we permute the shape
# such that it becomes (num_channels, num_frames, height, width) to make
# the shape compatible with the preprocessing transformations. After applying the
# preprocessing chain, we permute the shape to (num_frames, num_channels, height, width)
# to make it compatible with the model. Finally, we add a batch dimension so that our video
# classification model can operate on it.
video_tensor = torch.tensor(np.array(frames).astype(frames[0].dtype))
video_tensor = video_tensor.permute(
3, 0, 1, 2
) # (num_channels, num_frames, height, width)
video_tensor_pp = VAL_TRANSFORMS(video_tensor)
video_tensor_pp = video_tensor_pp.permute(
1, 0, 2, 3
) # (num_frames, num_channels, height, width)
video_tensor_pp = video_tensor_pp.unsqueeze(0)
return video_tensor_pp.to(DEVICE)
def infer(video_file):
frames = parse_video(video_file)
video_tensor = preprocess_video(frames)
inputs = {"pixel_values": video_tensor}
# forward pass
with torch.no_grad():
outputs = MODEL(**inputs)
logits = outputs.logits
softmax_scores = torch.nn.functional.softmax(logits, dim=-1).squeeze(0)
confidences = {LABELS[i]: float(softmax_scores[i]) for i in range(len(LABELS))}
return confidences
Launch Gradio application
gr.Interface(
fn=infer,
inputs=gr.Video(type="file"),
outputs=gr.Label(num_top_classes=3),
examples=[
["examples/fight.mp4"],
["examples/baseball.mp4"],
["examples/balancebeam.mp4"],
["./examples/no-fight1.mp4"],
],
title="VideoMAE fin-tuned on a subset of Fight / No Fight dataset",
description=(
"Gradio demo for VideoMAE for video classification. To use it, simply upload your video or click one of the"
" examples to load them. Read more at the links below."
),
article=(
"<div style='text-align: center;'><a href='https://huggingface.co/docs/transformers/model_doc/videomae' target='_blank'>VideoMAE</a>"
" <center><a href='https://huggingface.co/archit11/videomae-base-finetuned-fight-nofight-subset2' target='_blank'>Fine-tuned Model</a></center></div>"
),
allow_flagging=False,
allow_screenshot=False,
).launch()
Results & Discussions
Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 252
- mixed_precision_training: Native AMP
Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|---|---|---|---|---|
| 0.5145 | 0.25 | 64 | 0.7845 | 0.5075 |
| 0.607 | 1.25 | 128 | 0.6886 | 0.6343 |
| 0.3986 | 2.25 | 192 | 0.5106 | 0.7463 |
| 0.3632 | 3.24 | 252 | 0.7408 | 0.6716 |